Does the theory presented in the previous article work in practice? That is the theme of this post where I present an (anonymous) case from a project I did for a customer.
But before I proceed, a quick reminder from my book “Business Analysis for Business Intelligence”.
What every organisation needs to know boils down to four C’s. It is information about the customer, the cost, the competition and the competences of the organisation, the latter also represented by a higher level of abstraction: the capabilities.
The illustration below shows how these four C’s are the foundation of a balanced scorecard. But a balanced scorecard measures only the intended –or planned- strategy, not the emergent strategies. Therefore, this 4 C framework has a much broader scope and includes decision support for emergent strategies.

To develop a shared knowledge of the customer, this organisation needed to embed a business rule in the data namely that contacts are associated with an account. This, because the organisation is an exclusive business-to-business marketing machine selling to large corporations. A contact without this association was registered and kept in a staging area, waiting to be associated with an account. In other words: only contacts related to an organisation were of use to the business. At least, in the present context.

Today, this rule is cast in stone in a
monolithic CRM application but the CIO wishes to migrate to a service factory
in the near future. This way, when the business rule would change or when the
company would move to a B2C market, the CRM processes would be easier to adapt
to the new situation. A transition plan for all customer data needs to be
developed.
Lingua Franca used the following phased
approach:
- · Mapping the customer data in a data portfolio
- · Study the ASIS
- · Link capabilities to analytics
- · Map the capabilities on the data portfolio
- · Define the information landscape
- · Make the mapping analytics – transactional data
- · Define the services
- · Decide on the physical architecture

Mapping the customer data in a data portfolio
A lot of customer data is of strategic value and a lot isn’t. That led us to use a modified version of McFarlan’s portfolio approach to information systems which can just as well be applied to data.
Variant on: McFarlan, F. W. (1981). "Portfolio approach to information systems.
"Harvard Business Review (September–October 1981): 142-150
The analytics version of this schema translates the four quadrants into workable definitions:
Strategic Data: critical to future strategy development: both forming and executing strategy are supported by the data, as well as emergent strategies where data might be captured outside the exiting process support systems. The reason is clear: process support or transaction support systems are designed and tuned for the intended strategy.
Turnaround Data: critical to future business success as today’s operations are not supported, new operations will be needed to execute. These data are often not even in scope of the emergent strategy processes. They may be hidden in a competitor’s research, in technological breakthroughs, in new government regulations or in consumer outcries against abuse to name a few sources.
Support Data: Valuable but not critical to success
Factory Data: critical to existing business operations: the classical reports, dashboards and scorecards
In this case, the association between account and contact was considered factory data as it describes the way the company is doing business today
As the illustration below in the Archimate model shows, there is a cascading flow of business drivers and stakeholders that influence the business goals which in their turn impact the requirements that are realised by business processes. These are supported by legacy systems and new software packages or bespoke applications. The result of this approach is a dispersed view on the data that are used and produced in these applications. What if not processes but data would be at the base of the requirements? Would this change the organisation’s agility? Would it enhance responsiveness to external influence? That was the exercise we were preparing for.
 |
| Data dispersion in a classical IT landscape |
.
Study the ASIS
Today, the business process of account and contact registrations is as follows:
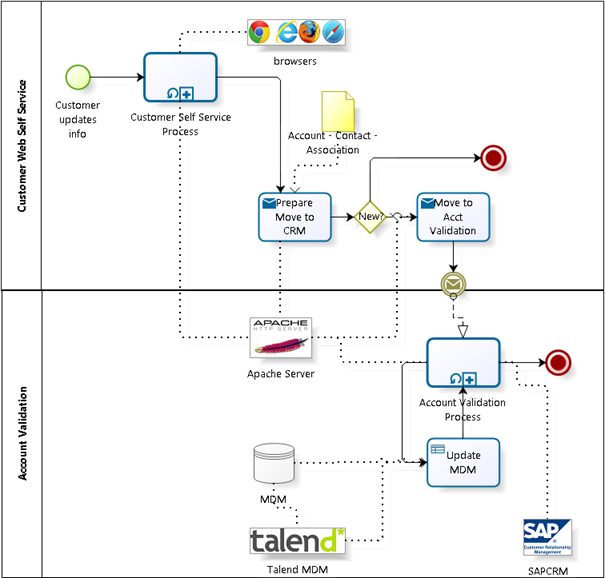
The present CRM monolith supports this process but future developments like the takeover of a more consumer oriented business may change the business model and the business process drastically. Thus, the self-service registration process should make the link between contact and account optional and the validation process should only deal with harmonising data to make sure the geographical information is correct and contact data are uniform as far as (internal) naming conventions and (external) reference data are concerned. It is already a great step forward that the company uses a master data management system to separate data management from process management. This enables a smoother transition to the new information architecture development method.
Link capabilities to analytics
Therefore an extensive inventory of all potentially needed business capabilities is undertaken and linked to the relevant business questions supporting these capabilities.
In this example we present a few of these present and future business questions:
What is the proportion of contacts from our B2B customers that may be interested in our consumer business?
Which accounts may experience a potential threat from our new consumer business unit?
Which contacts from the B2C may become interested in our B2B offerings?
Which products from the B2C unit may prove sellable via the B2B channels?
By listing all the relevant present and future business questions, it becomes clear that the account validation process as it is defined today may need to change and what is considered factory data today may get an “upgrade” to strategic and turnaround data to deal with the challenges.
Map the capabilities on the data portfolio
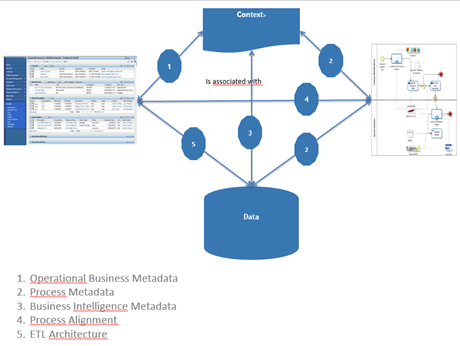
In this diagram, the entire data landscape of the account – contact association is charted and managed via five methods.
Operational business metadata describe the context in which data is created, updated and deleted as well as the context in which it is used. A minimum deliverable is instructions and training for the people who perform the CRUD operations.Process metadata relates the business process (present and future) to the business context to provide the process stakeholders with information and motivation: the what, why, when and who of the process and the data captured.Business Intelligence metadata describes the decision support possibilities in the present and future clients: dashboards, reports, cubes, data sets for further examination,…Process alignment: it describes what is often a mutual adjustment between a monolithic application and the business process it supports. Some market leaders in OLTP software present their process flows as best practice. As if all businesses should converge in their way of doing business…ETL Architecture documents the lineage from source to target, the transformations, quality measures, as well as the technical aspects of the process i.e. parallel or sequential loading, dropping of indexes and rebuilding them, hashing, etc… Define the information landscape
Even in this simple customer – account relationship some thinking needs to be done about a holistic view on the essential elements defining the relationship. By “essential” I mean the minimum attributes and levels of detail that need to be shared outside the context of CRM to be used in other business functions like HR, operations, finance,…
Here are a few of the considerations to be made:
How long is a customer considered as such? If the average buying frequency of your product is twice a year, for how many years do you keep the relationship active if for three years no order has come in? How do we compare the account performance in case of mergers? Does an account always need a DUNS number? Or a VAT registration? What about informal groups regularly doing group purchases? Discussing these and many other issues lays the foundation for a data governance process.
Make the mapping analytics – transactional data
This phase is crucial for the quality of your decision support system and is very much like the business analysis process for analytics. Start with high level concepts and descend to the lowest grain of attributes and transaction records as well as external sources like social media, open data and market research data.For instance: “customer loyalty” is expressed as “a constantly high share of wallet over an average historic period of time of three years and a projected future loyalty period of another three years”.
Can you imagine the data needed to make this definition work?
The exercise at this customer’s site produced 87 different data types coming from the ERP and CRM systems as well as external data like Net Promotor Scores, contact centre chat data, e-mails and response to LinkedIn posts. It sparked new ways of customer interaction procedures: new sales and order processing methods as well as new aftersales initiatives, the organisation would never have come up with if it hadn’t done this exercise.
Define the services
To move from the monolithically based approach to a more micro service oriented architecture, we needed to decompose the monolith into distinctive reusable services and data components. This approach forces a strict quality management for the data in scope as errors or poor quality will reflect on an enterprise scale. On the other hand, this “do it right the first time” principle avoids replication of work and improves the quality of decision making drastically.The schema below needs some explanation. The intake service triggers the validation service which checks the contact and account data with reference data, Chamber of Commerce data and, when finished, triggers the registration service which in its turn triggers the master data update service. MDM contact is now a superclass of this contact and will be used enterprise wide. Four services now ensure reusability for not just the CRM application but for all other use cases in the organisation. And the data quality improves drastically as the “do-it-right-the-first-time” principle is easier to fund for enterprise wide data.
 |
| Data landscape for a CRM and customer MDM application |
Decide on the physical architecture
The classical approach using at least two environments is becoming obsolete for organisations that want to stay ahead of the competition. The separation between transaction processing and analytical processing will go out the window in the next few years. Not only because of the costly maintenance of Extract Transform and Load (ETL) processes between the transaction systems and the data warehouse but first and foremost because of the lack of integration with unstructured data that are in Hadoop Distributed File Sets (HDFS) or streaming data that are caught in Resilient Distributed Datasets (RDD)
The organisation needs a significant leap forward and is now examining the Vector in Hadoop solution, a database that combines the classic SQL environment with NoSQL. The reasons are supported by objective facts: a rapidly scalable full ACID SQL database based on HDFS. It supports modify, insert and updates using a patented technology developed at the University of Amsterdam: the Positional Delta Trees (PDT). More on this in their paper which is published here. The short version of PDT: a separation between the write and read store where updates are merged into the write store at run time using the row index for a correct positioning of the modify/insert or update. The result? Online updates without impacting the read performance. Since the database can also access Spark’s parallel processing capability combining Spark RDD architecture accessed from the SQL perspective so that queries that were previously impossible to consider, this system combines the very best of three worlds: ACID based transaction support, complex event processing and HDFS support for unstructured data analytics with a flexible approach to changing data influx –provided you do your homework and define the column families in the broadest possible sense to fit your analytical needs.
Data loading – if that is the purpose - can be achieved at a rate of around 4TB per hour comprising four billion ‘120 column’ tuples per hour on a 10 node Hadoop cluster – or around 500 billion columns per hour in total! (many caveats apply but it is still a remarkable performance.
The advantage of this architecture will be exploited to the maximum if the data architecture is connecting transaction data, which are by definition microscopic and consistent, to analytical concepts which are macroscopic, flexible and fuzzy. So here is –finally!- my sales pitch: do your proper business analysis for analytics well. Because the cost of preparing for a well thought through system is a fraction of the license-, hardware- and maintenance cost.
Epilogue: an initial approach
A first attempt to map the various data ingestions to Vector H and the consumers of the data was made as illustrated below. This has a few consequences we will discuss in the next few paragraphs.

A more in depth example of Vector H’s power
One aspect will be along the Spark line – the ease of facilitating combined queries that incorporate data that is held in Hadoop with managed structured data in a way that standard BI tools simply query the database in the same way that they do a standard SQL database. I.e. the user does not need to use ETL or ELT separately from the actual BI query for ad-hoc queries once they have defined the external table as referencing the Hadoop data. It is hard to define the simplification this brings. In its simple form – it’s like the data really is inside the Vector database. This brings the advantage that current solutions – including off the peg turnkey applications can access this data.
This example shows the declaration made by the DBA, once this is done, the end users’ business layer will simply see ‘tweets’ as a table that can be joined to actual tables
CREATE EXTERNAL TABLE tweets
(username VARCHAR(20),
tweet VARCHAR(100),
timestamp VARCHAR(50))
USING SPARK
WITH REFERENCE='hdfs://blue/tmp/twitter.avro',
FORMAT='com.databricks.spark.avro'
This command will select tweets that are made which are from customers only, those from non-customers will be ignored:
SELECT tw.username , cust.firstname, cust.lastname, tw.tweet
FROM tweets tw,
Customers cust
WHERE tw.username = cust.username
AND tw.Timestamp > TIMESTAMPDIFF( SECONDS, 120, CURRENT_TIMESTAMP )
\g
Similar queries can track non-customer queries.
Where possible restrictions will be pushed down to the Spark ( Map Reduce and Scala level ) in Hadoop to be answered. The data never needs to be stored. Of course some data may be required to be added to the structured data. I already applied this in a customer analysis project where I illustrated how the results from Big Data analytics can be transformed to dimensions in the “classical” data warehouse:

To conclude: will hybrid architectures make data modelling obsolete?
I can’t yet generalise this for all hybrid databases but at least from Vector H we know that there is a serious chance. It uses a partition clause that distributes data on the hash of one or more columns that have a minimum of 10X unique values evenly distributed as the number of partitions you are using.
Vector H is therefore the most model agnostic data store I know. You simply create a schema, load data and run queries. There is no need for indexing or some form of normalisation with this technology.
Whereas the need for 3NF, Data Vault or Star schemas may become less important, governing these massive amounts of data in a less organised way may become the principal issue to focus on. And metadata management may become the elephant in the room.
I think hybrid databases have a bright but distant future as most companies are heavily invested in their present infrastructure and are still discovering the possibilities of Hadoop and Spark...
BeantwoordenVerwijderenThat is the case with all IT investments. Mainframes have been declared dead many times...
BeantwoordenVerwijderen